数据结构与算法 笔记 基本概念 一、数据结构 1. 其他定义
数据结构是数据对象,以及存在于该对象的实例和组成实例的数据元素之间的各种联系。这些联系可以通过定义相关的函数来给出。 ——Sartaj Sahni 《数据结构、算法与应用》
数据结构是 ADT(Abstract Data Type,数据抽象类型)的物理实现。 ——Clifford A.Shaffer 《数据结构与算法分析》
数据结构(data structure)是计算机中存储、组织数据的方式。通常情况下,精心选择的数据结构可以带来最优效率的算法。 ——中文维基百科
2. 解决问题方法的效率
跟数组的组织方式有关
跟空间的利用效率有关
跟算法的巧妙程度有关
3. 最终定义
数据对象在计算机中的组织方式
数据对象必定与一系列加在其上的操作相关联
完成这些操作所用的方法就是算法
4. 抽象数据类型(Abstract Data Type)
数据类型
抽象:描述数据类型的方法不依赖于具体实现
与存放数据的机器无关
与数据存储的物理结构无关
与实现操作的算法和编程语言均无关
只描述数据对象集和相关操作集“是什么”,并不涉及“如何做到”的问题
二、算法 1. 定义
一个有限指令集
≥ 0 的输入
==>==0 的输出
一定在有限步骤之后终止
每一条指令必须
有充分明确的目标,不可以有歧义
计算机能处理范围内
描述应不依赖于任何一种计算机语言以及具体的实现手段
2. 描述算法的手段
空间复杂度 S(n)
根据算法写成的程序在执行时占用存储空间的长度
时间复杂度 T(n)
根据算法写成的程序在执行时耗费的时间的长度
3. 评价
在分析一般算法的效率时,常常关注
最坏情况复杂度$T_{\text {worst}}(n)$
平均情况复杂度 $T_{\text {avg}}(n)$
$T_{\text {avg}}(n) \leq T_{\text {worst}}(n)$
一般情况下更多关注的是最坏情况复杂度
4. 复杂度的渐进表示法
$T(n)=O(f(n))$ 表示存在常数 $\mathrm{C}>0, n_{0}>0,$ 使得当 $n \geq n_{0}$ 时有 $T(n) \leq$$C \cdot f(n),$ 即 $O(f(n))$ 表示 $f(n)$ 是 $\mathrm{T}(\mathrm{n})$ 的某种上界
$T(n)=\Omega(g(n))$ 表示存在常数 $\mathrm{C}>0, n_{0}>0,$ 使得当 $n \geq n_{0}$ 时有 $T(n) \geq$$C \cdot g(n),$ 即 $\Omega(g(n))$ 表示 $g(n)$ 是 $\mathrm{T}(\mathrm{n})$ 的某种下界
$T(n)=\theta(h(n))$ 表示同时有 $T(n)=O(h(n))$ 和 $T(n)=\Omega(h(n)),$ 即$\theta(h(n))$ 既是上界也是下界
5. 复杂度分析小窍门
若两段算法分别有复杂度 $T_{1}(n)=O\left(f_{1}(n)\right)$ 和 $T_{2}(n)=O\left(f_{2}(n)\right),$ 则
若 $T(n)$ 是关于 $n$ 的 $k$ 阶多项式, 那么 $T(n)=\theta\left(n^{k}\right)$
一个 for 循环的时间复杂度等于循环次数乘以循环体代码的复杂度
if-else 结构的复杂度取决于 if 的条件判断复杂度和两个分枝部分的复杂度,总体复杂 度取三者中最大
线性表 1. 什么是线性表 “线性表”:由同类型数据元素构成有序序列的线性结构
表中元素个数称为线性表的长度
线性表没有元素时,称为空表
表起始位置称为表头 ,表结束位置称表尾
2. 线性表的抽象数据类型描述
类型名称:线性表(List)
数据对象集:线性表是 n (≥0) 个元素构成的有序序列$\left(a_{1}, a_{2}, \ldots, a_{n}\right)$
操作集:线性表 L ∈ List,整数 i 表示位置,元素 X ∈ ElementType
线性表基本操作主要有:
List MakeEmpty(): 初始化一个空线性表 LElementType FindKth(int K,List L):根据位序 K,返回相应元素int Find(ElementType X,List L):在线性表 L 中查找 X 的第一次出现位置void Insert(ElementType X,int i,List L):在位序 i 前插入一个新元素 Xvoid Delete(int i,List L):删除指定位序 i 的元素int Length(List L):返回线性表 L 的长度 n
1. 线性表的顺序存储实现 利用数组的连续存储空间顺序存放线性表的各元素
注:顺序存储中是序号是下标,从 0 开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 #include <stdio.h> #include <malloc.h> #define MAXSIZE 100 typedef int ElementType; typedef struct LNode *List ;struct LNode { ElementType Data[MAXSIZE]; int Last; }; List L; List MakeEmpty () ; int Find (ElementType X,List L) void Insert (ElementType X,int i,List L) void Delete (int i,List L) ElementType FindKth (int K,List L) ; int Length (List L) List MakeEmpty () { List L; L = (List)malloc (sizeof (struct LNode)); L->Last = -1 ; return L; } int Find (ElementType X,List L) int i=0 ; while (i <= L->Last && L->Data[i] != X) i++; if (L->Last < i) return -1 ; else return i; } void Insert (ElementType X,int i,List L) int j; if (L->Last == MAXSIZE-1 ){ printf ("表满" ); return ; } if (i < 0 || L->Last+1 < i){ printf ("位置不合法" ); return ; } for (j=L->Last;j>=i;j--) L->Data[j+1 ] = L->Data[j]; L->Data[i] = X; L->Last++; return ; } void Delete (int i,List L) int j; if (i < 0 || L->Last <i){ printf ("L->Data[%d]不存在元素" ,i); return ; } for (j=i;j<=L->Last;j++) L->Data[j-1 ] = L->Data[j]; L->Last--; return ; } ElementType FindKth (int K,List L) { if (K < 0 || L->Last < K){ printf ("L->Data[%d]不存在元素" ,K); return ; } return L->Data[K]; } int Length (List L) return L->Last+1 ; } int main () int i=0 ; L = MakeEmpty(); Insert(11 ,0 ,L); printf ("在线性表L-Data[0]插入11\n" ); Insert(25 ,0 ,L); printf ("在线性表L-Data[0]插入25\n" ); Insert(33 ,0 ,L); printf ("在线性表L-Data[0]插入33\n" ); Insert(77 ,0 ,L); printf ("在线性表L-Data[0]插入77\n" ); printf ("此时的线性表为:" ); for (i=0 ;i<Length(L);i++) printf ("%d " ,L->Data[i]); printf ("\n" ); printf ("查找值为12的下标是:%d\n" ,Find(12 ,L)); printf ("下标为3的线性表的值是:%d\n" ,FindKth(3 ,L)); Delete(2 ,L); printf ("删除线性表中下标为2的元素\n" ); Delete(2 ,L); printf ("删除线性表中下标为2的元素\n" ); printf ("此时的线性表为:" ); for (i=0 ;i<Length(L);i++) printf ("%d " ,L->Data[i]); printf ("\n" ); return 0 ; }
2. 线性表的链表存储实现 不要求逻辑上相邻的两个元素物理上也相邻,通过”链”建立起数据之间的逻辑关系
注:链表存储中序号从 1 开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 #include <stdio.h> #include <malloc.h> typedef int ElementType; typedef struct LNode *List ;struct LNode { ElementType Data; List Next; }; List L; List MakeEmpty () ; int Length (List L) List FindKth (int K,List L) ; List Find (ElementType X,List L) ; List Insert (ElementType X,int i,List L) ; List Delete (int i,List L) ; void Print (List L) List MakeEmpty () { List L = (List)malloc (sizeof (struct LNode)); L = NULL ; return L; } int Length (List L) List p = L; int len=0 ; while (p){ p = p->Next; len++; } return len; } List FindKth (int K,List L) { List p = L; int i = 1 ; while (p && i<K){ p = p->Next; i++; } if (i == K) return p; else return NULL ; } List Find (ElementType X,List L) { List p = L; while (p && p->Data!=X) p = p->Next; return p; } List Insert (ElementType X,int i,List L) { List p,s; if (i == 1 ){ s = (List)malloc (sizeof (struct LNode)); s->Data = X; s->Next = L; return s; } p = FindKth(i-1 ,L); if (!p){ printf ("结点错误" ); return NULL ; }else { s = (List)malloc (sizeof (struct LNode)); s->Data = X; s->Next = p->Next; p->Next = s; return L; } } List Delete (int i,List L) { List p,s; if (i==1 ){ s = L; if (L) L = L->Next; else return NULL ; free (s); return L; } p = FindKth(i-1 ,L); if (!p || !(p->Next)){ printf ("结点错误" ); return NULL ; }else { s = p->Next; p->Next = s->Next; free (s); return L; } } void Print (List L) List t; int flag = 1 ; printf ("当前链表为:" ); for (t = L;t;t =t->Next){ printf ("%d " ,t->Data); flag = 0 ; } if (flag) printf ("NULL" ); printf ("\n" ); } int main () L = MakeEmpty(); Print(L); L = Insert(11 ,1 ,L); L = Insert(25 ,1 ,L); L = Insert(33 ,2 ,L); L = Insert(77 ,3 ,L); Print(L); printf ("当前链表长度为:%d\n" ,Length(L)); printf ("此时链表中第二个结点的值是:%d\n" ,FindKth(2 ,L)->Data); printf ("查找22是否在该链表中:" ); if (Find(22 ,L)) printf ("是!\n" ); else printf ("否!\n" ); printf ("查找33是否在该链表中:" ); if (Find(33 ,L)) printf ("是!\n" ); else printf ("否!\n" ); L = Delete(1 ,L); L = Delete(3 ,L); printf ("----------删除后-----\n" ); Print(L); return 0 ; }
堆栈 1. 什么是堆栈 堆栈(Stack):具有一定操作约束的线性表
只在一端(栈顶,Top)做插入、删除
插入数据:入栈(Push)
删除数据:出栈(Pop)
后入先出:Last In First Out(LIFO)
2. 堆栈的抽象数据类型描述
1. 栈的顺序存储实现 栈的顺序存储结构通常由一个一维数组和一个记录栈顶元素位置的变量组成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <stdio.h> #include <malloc.h> #define MaxSize 100 typedef int ElementType; typedef struct SNode *Stack ;struct SNode { ElementType Data[MaxSize]; int Top; }; Stack S; Stack CreateStack () ; int IsFull (Stack S) int IsEmpty (Stack S) void Push (Stack S,ElementType item) ElementType Pop (Stack S) ; Stack CreateStack () { S = (Stack)malloc (sizeof (struct SNode)); S->Top = -1 ; return S; } int IsFull (Stack S) return (S->Top == MaxSize-1 ); } int IsEmpty (Stack S) return (S->Top == -1 ); } void Push (Stack S,ElementType item) if (IsFull(S)){ printf ("堆栈满" ); return ; }else { S->Top++; S->Data[S->Top] = item; return ; } } ElementType Pop (Stack S) { if (IsEmpty(S)){ printf ("堆栈空" ); return ; }else { ElementType val = S->Data[S->Top]; S->Top--; return val; } } int main () S = CreateStack(); printf ("5入栈\n" ); Push(S,5 ); printf ("7入栈\n" ); Push(S,7 ); printf ("66入栈\n" ); Push(S,66 ); printf ("%d出栈\n" ,Pop(S)); printf ("%d出栈\n" ,Pop(S)); return 0 ; }
2. 栈的链表存储实现 栈的链式存储结构实际上就是一个单链表,叫做链栈。插入和删除操作只能在链栈的栈顶进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <stdio.h> #include <malloc.h> typedef int ElementType;typedef struct SNode *Stack ;struct SNode { ElementType Data; Stack Next; }; Stack CreateStack () ; int IsEmpty (Stack S) void Push (Stack S,ElementType item) ElementType Pop (Stack S) ; Stack CreateStack () { Stack S; S = (Stack)malloc (sizeof (struct SNode)); S->Next = NULL ; return S; } int IsEmpty (Stack S) return (S->Next == NULL ); } void Push (Stack S,ElementType item) Stack tmp; tmp = (Stack)malloc (sizeof (struct SNode)); tmp->Data = item; tmp->Next = S->Next; S->Next = tmp; } ElementType Pop (Stack S) { Stack First; ElementType TopVal; if (IsEmpty(S)){ printf ("堆栈空" ); return ; }else { First = S->Next; S->Next = First->Next; TopVal = First->Data; free (First); return TopVal; } } int main () Stack S; S = CreateStack(); printf ("5入栈\n" ); Push(S,5 ); printf ("7入栈\n" ); Push(S,7 ); printf ("66入栈\n" ); Push(S,66 ); printf ("%d出栈\n" ,Pop(S)); printf ("%d出栈\n" ,Pop(S)); return 0 ; }
队列 1. 什么是队列 队列(Queue):具有一定操作约束的线性表
插入和删除操作:只能在一端(front)插入,而在另一端(rear)删除
数据插入:入队列(AddQ)
数据删除:出队列(DeleteQ)
先进先出:FIFO
2. 队列的抽象数据类型描述
1. 循环队列的顺序存储实现 队列的顺序存储结构通常由一个一维数组和一个记录队列头元素位置的变量 front 以及一个记录队列尾元素位置的变量 rear 组成,其中 front 指向整个队列的头一个元素的再前一个,rear 指向的是整个队列的最后一个元素,从 rear 入队,从 front 出队,且仅使用 n-1 个数组空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <stdio.h> #include <malloc.h> #define MaxSize 100 typedef int ElementType;typedef struct QNode *Queue ;struct QNode { ElementType Data[MaxSize]; int front; int rear; }; Queue CreateQueue () ; void AddQ (Queue Q,ElementType item) int IsFull (Queue Q) ElementType DeleteQ (Queue Q) ; int IsEmpty (Queue Q) Queue CreateQueue () { Queue Q; Q = (Queue)malloc (sizeof (struct QNode)); Q->front = -1 ; Q->rear = -1 ; return Q; } int IsFull (Queue Q) return ((Q->rear+1 ) % MaxSize == Q->front); } void AddQ (Queue Q,ElementType item) if (IsFull(Q)){ printf ("队列满" ); return ; }else { Q->rear = (Q->rear+1 ) % MaxSize; Q->Data[Q->rear] = item; } } int IsEmpty (Queue Q) return (Q->front == Q->rear); } ElementType DeleteQ (Queue Q) { if (IsEmpty(Q)){ printf ("队列空" ); return 0 ; }else { Q->front = (Q->front+1 ) % MaxSize; return Q->Data[Q->front]; } } int main () Queue Q; Q = CreateQueue(); AddQ(Q,3 ); printf ("3入队\n" ); AddQ(Q,5 ); printf ("5入队\n" ); AddQ(Q,11 ); printf ("11入队\n" ); printf ("%d出队\n" ,DeleteQ(Q)); printf ("%d出队\n" ,DeleteQ(Q)); return 0 ; }
2. 队列的链式存储实现 队列的链式存储结构也可以用一个单链表实现。插入和删除操作分别在链表的两头进行,front 在链表头,rear 在链表尾,从 rear 入队,从 front 出队
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <stdio.h> #include <malloc.h> typedef int ElementType;typedef struct QNode *Queue ;struct Node { ElementType Data; struct Node *Next ; }; struct QNode { struct Node *rear ; struct Node *front ; }; Queue CreateQueue () ; void AddQ (Queue Q,ElementType item) ElementType DeleteQ (Queue Q) ; int IsEmpty (Queue Q) Queue CreateQueue () { Queue Q; Q = (Queue)malloc (sizeof (struct QNode)); Q->front = NULL ; Q->rear = NULL ; return Q; } int IsEmpty (Queue Q) return (Q->front == NULL ); } void AddQ (Queue Q,ElementType item) struct Node *node ; node = (struct Node *)malloc (sizeof (struct Node)); node->Data = item; node->Next = NULL ; if (Q->rear==NULL ){ Q->rear = node; Q->front = node; }else { Q->rear->Next = node; Q->rear = node; } } ElementType DeleteQ (Queue Q) { struct Node *FrontCell ; ElementType FrontElem; if (IsEmpty(Q)){ printf ("队列空" ); return 0 ; } FrontCell = Q->front; if (Q->front == Q->rear){ Q->front = Q->rear = NULL ; }else { Q->front = Q->front->Next; } FrontElem = FrontCell->Data; free (FrontCell); return FrontElem; } int main () Queue Q; Q = CreateQueue(); printf ("入队5\n" ); AddQ(Q,5 ); printf ("入队4\n" ); AddQ(Q,4 ); printf ("入队4\n" ); AddQ(Q,3 ); printf ("出队%d\n" ,DeleteQ(Q)); printf ("出队%d\n" ,DeleteQ(Q)); printf ("出队%d\n" ,DeleteQ(Q)); printf ("%d\n" ,DeleteQ(Q)); return 0 ; }
树 1. 树的定义 树(Tree):n(n≥0)个结点构成的有限集合
当 n=0 时,称为空树
1. 特征 对于任一棵非空树(n>0),它具备以下特征:
树中有个称为“根(Root)”的特殊结点,用 r 表示
其余结点可分为 m(m>0) 个互不相交的有限集$\mathrm{T}_{1}, \mathrm{T}_{2}, \ldots, \mathrm{T}_{m}$,其中每个集合本身又是一棵树,称为原来树的”子树(SubTree)”
子树是不相交的
除根结点外,每个结点有且仅有一个父结点
一棵 N 个结点的树有 N-1 条边
2. 基本术语
结点的度(Degree):结点的子树个数
树的度:树的所有结点中最大的度数
叶结点(Leaf):度为 0 的结点
父结点(Parent):有子树的结点是其子树的根结点的父结点
子结点(Child):若 A 结点是 B 结点的父结点,则称 B 结点是 A 结点的子结点,也称孩子结点
兄弟结点(Sibling):具有同一父结点的各个结点彼此是兄弟结点
路径:从结点 $\mathrm{n}_{1}$ 到 $\mathrm{n}_{k}$ 的路径为一个结点序列$\mathrm{n}_{1}, \mathrm{n}_{2}, \ldots, \mathrm{n}_{k}$,其中 $\mathrm{n}_{i}$是$\mathrm{n}_{i}$的父结点
路径长度:路径所包含边的个数
祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点
子孙结点(Descendant):某一结点的子树中的所有结点是这个结点的子孙
结点的层次(Level):规定根结点在 1 层,其他任一结点的层数是其父结点的层数加一
树的深度(Depth):树中所有结点中的最大层次是这棵树的深度
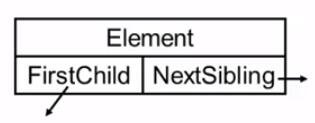
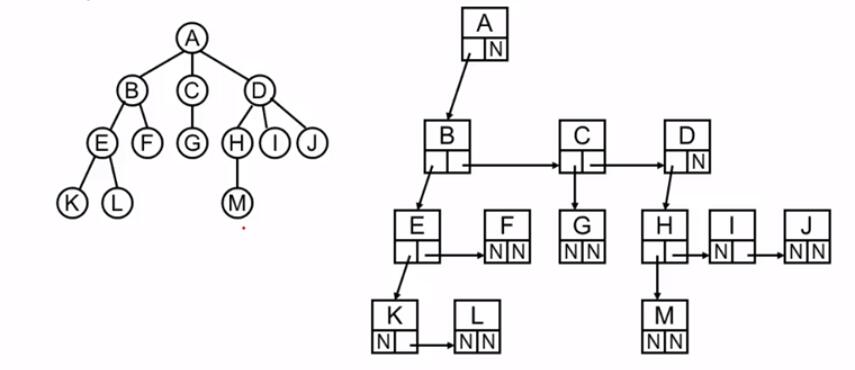
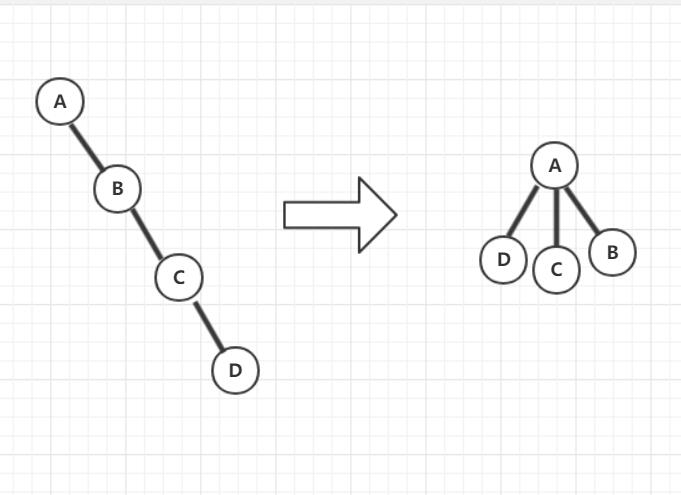
3. 树的表示 1. 儿子-兄弟表示法
Element 存值
FirstChild 指向第一个儿子
NextSibling 指向下一个兄弟
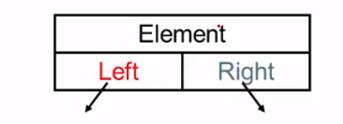
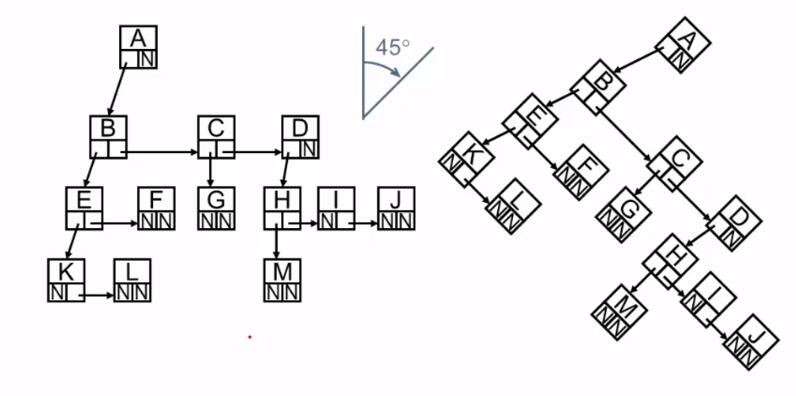
2. 二叉树 即度为 2 的树
Element 存值
Left 指向左子树
Right 指向右子树
二叉树其实就是儿子-兄弟表示法的链表右移 45° 得到的结果
2. 二叉树 1. 定义 二叉树 T:一个有穷的结点集合
这个集合可以为空
若不为空,则它是由根结点 和称为其左子树T L_LL 和右子树T R_RR 的两个不相交的二叉树组成
二叉树的子树有左右顺序之分
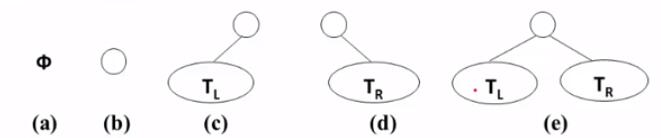
2. 五种基本形态
3. 特殊形态
4. 重要性质
一个二叉树第 i 层的最大结点数为:$2^{i-1}, i \geq1$
深度为 k 的二叉树有最大结点总数为:$2^{k}-1, k \geq 1$
对任何非空二叉树 T,若 $\mathrm {n}_{0}$表示叶结点的个数、$\mathrm {n}_{2}$是度为 2 的非叶结点个数,那么二者满足关系 $\mathrm {n}_{0} = {n}_{2}+1$
5. 抽象数据类型定义
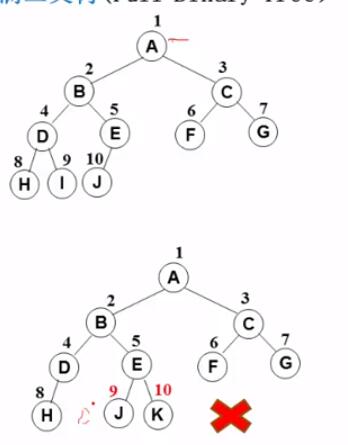
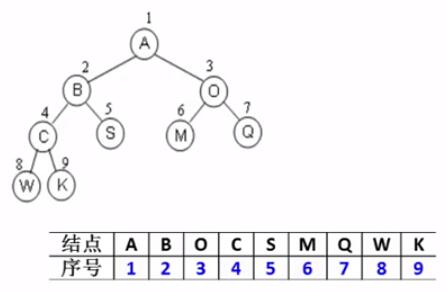
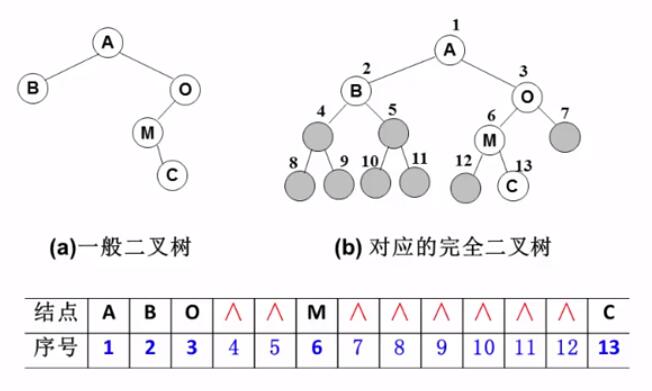
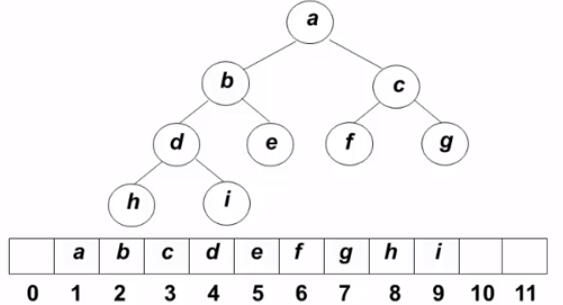
1. 顺序存储结构 按从上至下、从左到右顺序存储 n 个结点的完全二叉树的结点父子关系:
非根结点(序号 i > 1)的父结点 的序号是 ⌊i/2⌋(向下取整)
结点(序号为 i)的左孩子结点 的序号是 2i(若 2 i ≤ n,否则没有左孩子
结点(序号为 i)的右孩子结点 的序号是 2i+1(若 2 i +1 ≤ n,否则没有右孩子
2. 链表存储
1 2 3 4 5 6 typedef struct TreeNode *BinTree ;struct TreeNode { Element Data; BinTree Left; BinTree Right; };
二叉树的遍历 0. 树的表示 1 2 3 4 5 6 typedef struct TreeNode *BinTree ;struct TreeNode { int Data; BinTree Left; BinTree Right; };
1. 先序遍历 遍历过程:
访问根结点
先序 遍历其左子树 先序 遍历其右子树
1.递归实现 1 2 3 4 5 6 7 void PreOrderTraversal (BinTree BT) if (BT){ printf ("%d" ,BT->Data); PreOrderTraversal(BT->Left); PreOrderTraversal(BT->Right); } }
2. 非递归实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void PreOrderTraversal (BinTree BT) BinTree T = BT; Stack S = CreateStack(); while (T || !IsEmpty(S)){ while (T){ Push(S,T); printf ("%d" ,T->Data); T = T->Left; } if (!IsEmpty(S)){ T = Pop(S); T = T->Right; } } }
2.中序遍历 递归过程:
中序 遍历其左子树 访问根结点
中序 遍历其右子树
1. 递归实现 1 2 3 4 5 6 7 void InOrderTraversal (BinTree BT) if (BT){ InOrderTraversal(BT->Left); printf ("%d" ,BT->Data); InOrderTraversal(BT->Right); } }
2. 非递归实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void InOrderTraversal (BinTree BT) BinTree T = BT; Stack S = CreateStack(); while (T || !IsEmpty(S)){ while (T){ Push(S,T); T = T->Left; } if (!IsEmpty(S)){ T = Pop(S); printf ("%d" ,T->Data); T = T->Right; } } }
3. 后序遍历 遍历过程:
后序 遍历其左子树 后序 遍历其右子树 访问根结点
1. 递归实现 1 2 3 4 5 6 7 void PostOrderTraversal (BinTree BT) if (BT){ PostOrderTraversal(BT->Left); PostOrderTraversal(BT->Right); printf ("%d" ,BT->Data); } }
2. 非递归实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void PostOrderTraversal (BinTree BT) BinTree T = BT; Stack S = CreateStack(); vector <BinTree> v; Push(S,T); while (!IsEmpty(S)){ T = Pop(S); v.push_back(T); if (T->Left) Push(S,T->Left); if (T->Right) Push(S,T->Right); } reverse(v.begin (),v.end ()); for (int i=0 ;i<v.size ();i++) printf ("%d" ,v[i]->Data); }
4. 总结 先序、中序和后序遍历过程:遍历过程中经过结点的路线一样,只是访问各结点的时机不同,即:
先序遍历是第一次”遇到”该结点时访问
中序遍历是第二次”遇到”该结点(此时该结点从左子树返回)时访问
后序遍历是第三次”遇到”该结点(此时该结点从右子树返回)时访问
5. 层序遍历 遍历过程:从上至下,从左至右访问所有结点
队列实现过程:
根结点入队
从队列中取出一个元素
访问该元素所指结点
若该元素所指结点的左孩子结点非空,左孩子结点入队
若该元素所指结点的右孩子结点非空,右孩子结点入队
循环 1 - 4,直到队列中为空
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void LevelOrderTraversal (BinTree BT) queue <BinTree> q; BinTree T; if (!BT) return ; q.push(BT); while (!q.empty()){ T = q.front(); q.pop(); printf ("%d" ,T->Data); if (T->Left) q.push(T->Left); if (T->Right) q.push(T->Right); } }
6. 例子 1. 输出叶子结点 前序遍历加个没有孩子结点的约束即可
1 2 3 4 5 6 7 8 void FindLeaves (BinTree BT) if (BT){ if ( !BT->Left && !BT->Right) printf ("%d" ,BT->Data); FindLeaves(BT->Left); FindLeaves(BT->Right); } }
2. 树的高度 当前树的高度为其子树最大高度 +1
1 2 3 4 5 6 7 8 9 10 int GetHeight (BinTree BT) int hl,hr,maxh; if (BT){ hl = GetHeight(BT->Left); hr = GetHeight(BT->Right); maxh = (hl>hr)?hl:hr; return maxh+1 ; }else return 0 ; }
3. 由两种遍历序列确定二叉树 前提 :有一种序列必须是中序!
方法:
根据先序(或后序)遍历序列第一个(或最后一个)结点确定根结点
根据根结点在中序序列中分割出左右 两个子序列
对左子树和右子树分别递归使用同样的方法继续分解
例如:
前序:ABCDEFG
先序遍历为”根左右”,则 A 是根,对应可以划分出中序中:(CBD)A(FEG),CBD 为左子树,FEG 为右子树,再根据前序的 BCD,B 为根,划分出中序中 (C(B)D)A(FEG),则 C D 分别是 B 的左右子树…最后可得树为:
1 2 3 4 5 A / \ B E / \ / \ C D F G
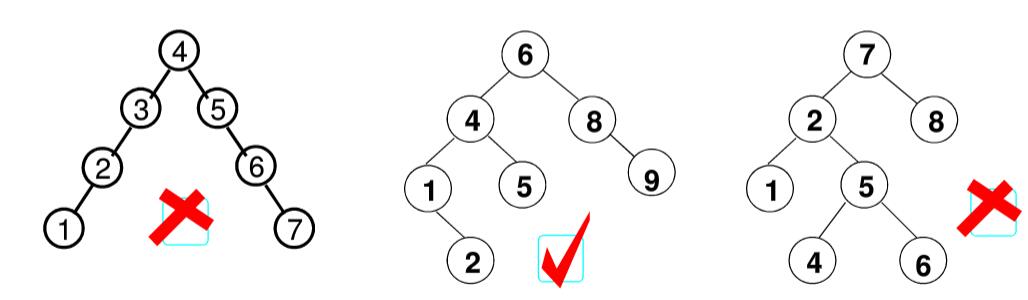
二叉搜索树 1. 定义 二叉搜索树(BST)也称二叉排序树或二叉查找树
二叉搜索树:一棵二叉树,可以为空;如果不为空,满足以下性质:
非空左子树 的所有键值小于 其根结点的键值
非空右子树 的所有键值大于 其根结点的键值
左、右子树都是二叉搜索树
2. 特殊函数
BinTree Find(ElementType X,BinTree BST):从二叉搜索树 BST 中查找元素 X,返回其所在结点地址BinTree FindMin(BinTree BST):从二叉搜索树 BST 中查找并返回最小元素所在结点的地址BinTree FindMax(BinTree BST):从二叉搜索树 BST 中查找并返回最大元素所在结点的地址BinTree Insert(ElementType X,BinTree BST):插入一个元素进 BSTBinTree Delete(ElementType X,BinTree BST):从 BST 中删除一个元素
1. 查找
查找从根结点开始,如果树为空,返回 NULL
若搜索树不为空,则根结点键值和 X 进行比较,并进行不同处理:
若 X 小于 根结点键值,在左子树 中继续查找
若 X 大于 根结点键值,在右子树 中继续查找
如 X 等于根节点键值,查找结束,返回指向此结点的指针
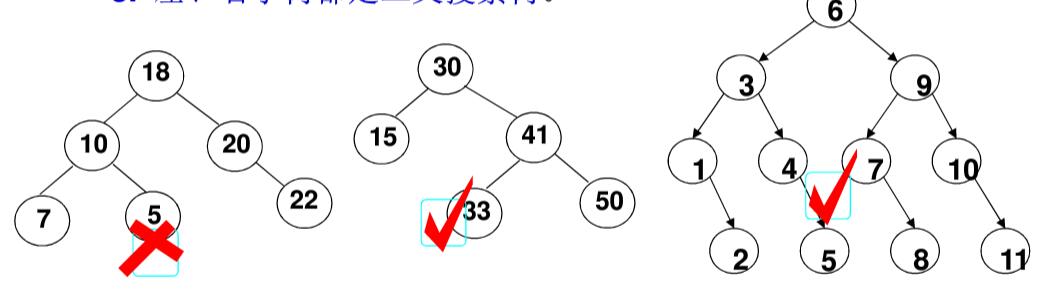
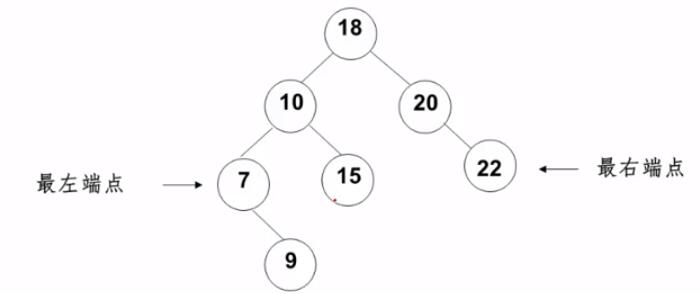
2. 查找最大和最小元素
最大元素 一定是在树的最右 分支的端结点上最小元素 一定是在树的最左 分支的端结点上
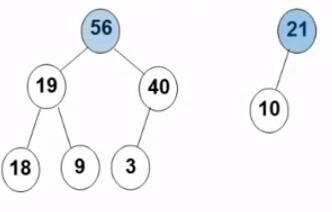
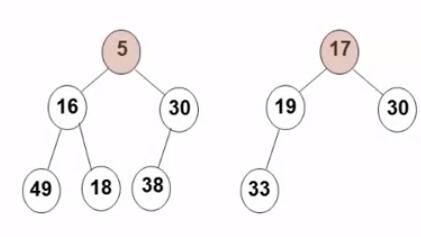
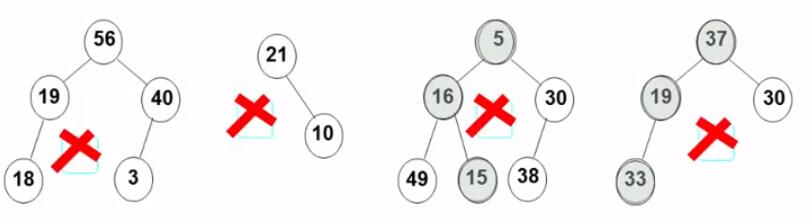
3. 删除 删除的三种情况:
要删除的是叶结点 :直接删除,并将其父结点指针置为 NULL
要删除的结点只有一个孩子 结点:将其父结点的指针指向要删除结点的孩子结点
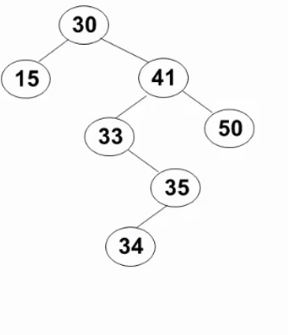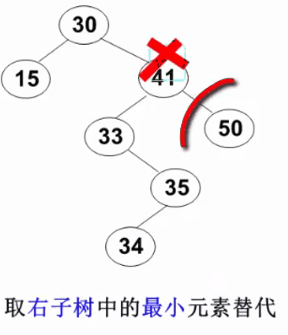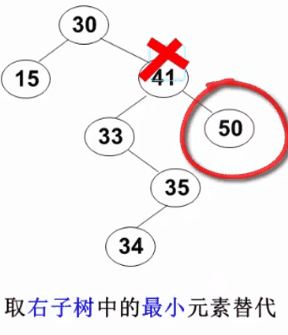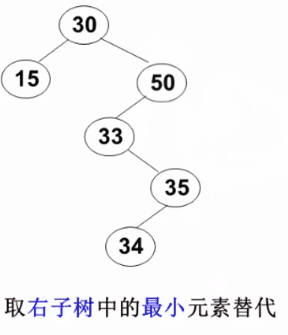
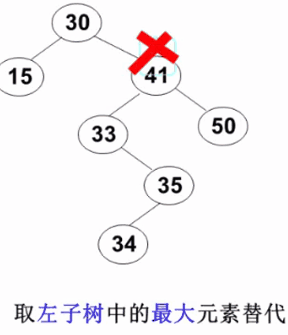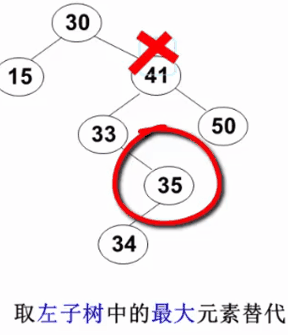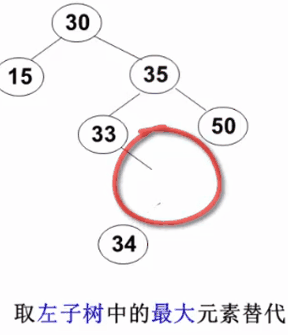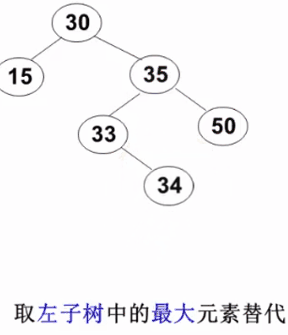
要删除的结点有左、右两棵子树:用右子树的最小元素 或左子树的最大元素 替代被删除结点
4. 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 #include <iostream> #include <malloc.h> using namespace std ;typedef int ElementType;typedef struct TreeNode *BinTree ;struct TreeNode { ElementType Data; BinTree Left; BinTree Right; }; BinTree Find (ElementType X,BinTree BST) { if (!BST) return NULL ; if (X < BST->Data) return Find(X,BST->Left); else if (BST->Data < X) return Find(X,BST->Right); else if (BST->Data == X) return BST; } BinTree IterFind (ElementType X,BinTree BST) { while (BST){ if (X < BST->Data) BST = BST->Left; else if (BST->Data < X) BST = BST->Right; else if (BST->Data == X) return BST; } return NULL ; } BinTree FindMin (BinTree BST) { if (!BST) return NULL ; else if (BST->Left) return FindMin(BST->Left); else return BST; } BinTree FindMax (BinTree BST) { if (BST) while (BST->Right) BST = BST->Right; return BST; } BinTree Insert (ElementType X,BinTree BST) { if (!BST){ BST = (BinTree)malloc (sizeof (struct TreeNode)); BST->Data = X; BST->Left = NULL ; BST->Right = NULL ; }else { if (X < BST->Data) BST->Left = Insert(X,BST->Left); else if (BST->Data < X) BST->Right = Insert(X,BST->Right); } return BST; } BinTree Delete (ElementType X,BinTree BST) { BinTree tmp; if (!BST) cout <<"要删除的元素未找到" ; else if (X < BST->Data) BST->Left = Delete(X,BST->Left); else if (BST->Data < X) BST->Right = Delete(X,BST->Right); else { if (BST->Left && BST->Right){ tmp = FindMin(BST->Right); BST->Data = tmp->Data; BST->Right = Delete(tmp->Data,BST->Right); }else { tmp = BST; if (!BST->Left && !BST->Right) BST = NULL ; else if (BST->Left && !BST->Right) BST = BST->Left; else if (!BST->Left && BST->Right) BST = BST->Right; free (tmp); } } return BST; } void InOrderTraversal (BinTree BT) if (BT){ InOrderTraversal(BT->Left); cout <<BT->Data; InOrderTraversal(BT->Right); } } int main () BinTree BST = NULL ; BST = Insert(5 ,BST); BST = Insert(7 ,BST); BST = Insert(3 ,BST); BST = Insert(1 ,BST); BST = Insert(2 ,BST); BST = Insert(4 ,BST); BST = Insert(6 ,BST); BST = Insert(8 ,BST); BST = Insert(9 ,BST); cout <<"中序遍历的结果是:" ; InOrderTraversal(BST); cout <<endl ; cout <<"查找最小值是:" <<FindMin(BST)->Data<<endl ; cout <<"查找最大值是:" <<FindMax(BST)->Data<<endl ; cout <<"查找值为3的结点左子树结点值为:" <<Find(3 ,BST)->Left->Data<<endl ; cout <<"查找值为7的结点右子树结点值为:" <<IterFind(7 ,BST)->Right->Data<<endl ; cout <<"删除值为5的结点" <<endl ; Delete(5 ,BST); cout <<"中序遍历的结果是:" ; InOrderTraversal(BST); cout <<endl ; return 0 ; }
平衡二叉树 0. 为何要使用AVL树? 二叉搜索树的搜索效率与其树的深度相关,而二叉搜索树的组成又与其插入序列相关,在极端情况下,二叉搜索树退化为一条单链(比如插入序列是 1 2 3 … n),使得搜索效率大大降低,为了避免这种情况出现,我们采用二叉平衡树对插入结点进行调整,使得树的深度尽可能小
1. 定义
平衡因子
平衡二叉树(AVL 树)
2. 平衡二叉树的调整 0. 遵循原则
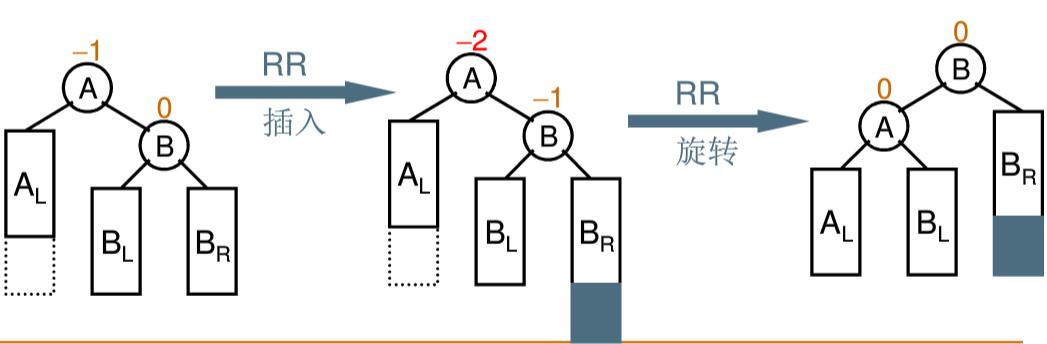
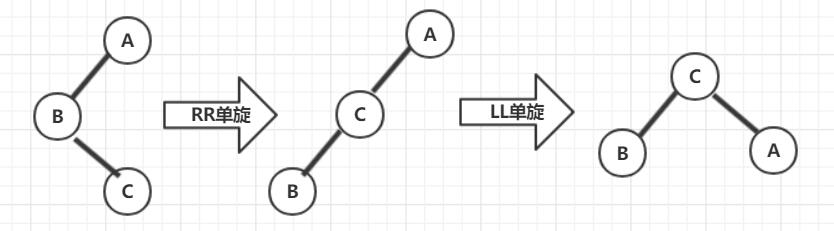
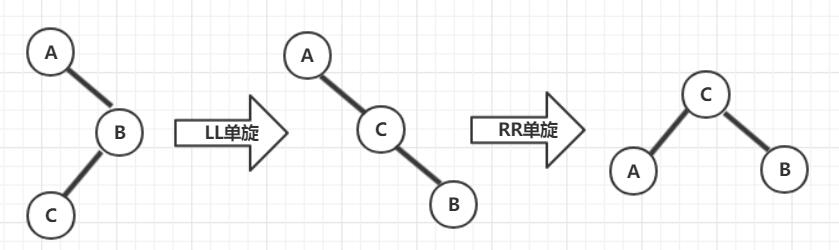
1. RR 单旋 当”插入结点”(BR)是”被破坏平衡结点”(A)右子树 的右子树 时,即 RR 插入时,采用 RR 旋转调整
示意图:
1 2 3 4 5 6 7 AVLTree RRRotation (AVLTree A) { AVLTree B = A->right; A->right = B->left; B->left = A; return B; } 123456
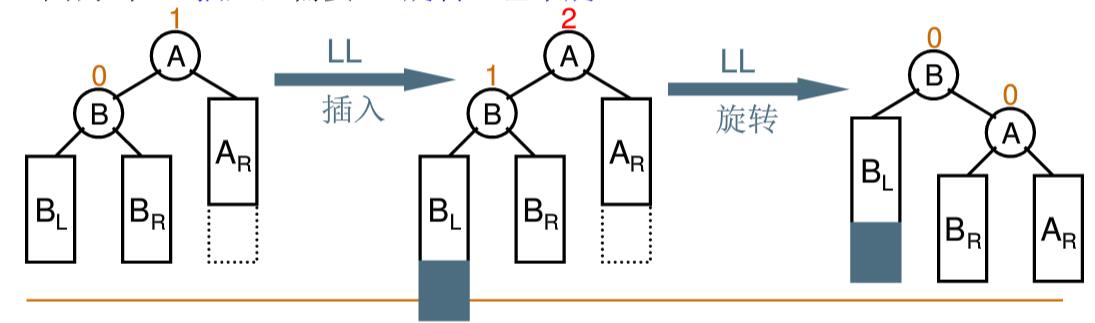
2. LL 单旋 当”插入结点”(BL)是”被破坏平衡结点”(A)左子树 的左子树 时,即 LL 插入,采用 RR 旋转调整
示意图:
1 2 3 4 5 6 7 8 AVLTree LLRotation (AVLTree A) { AVLTree B = A->left; A->left = B->right; B->right = A; return B; } 1234567
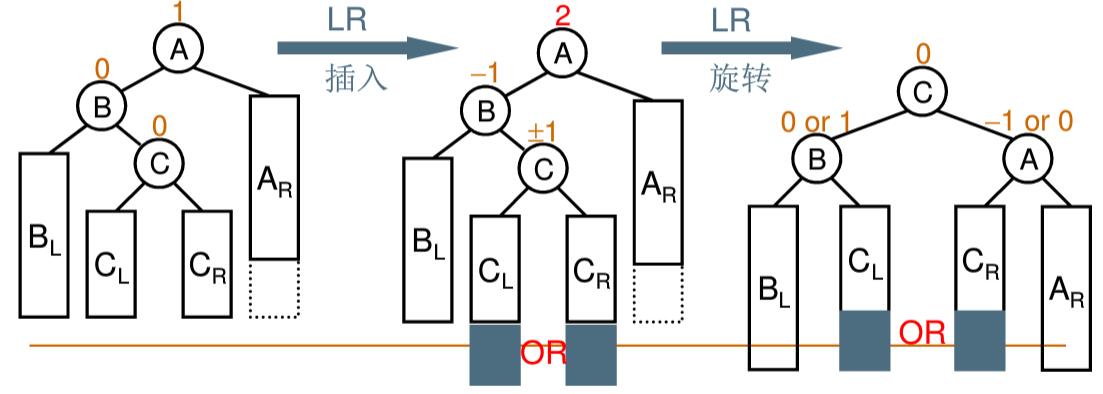
3. LR 双旋 当”插入结点”(CL 或者 CR)是”被破坏平衡结点”(A)左子树 的右子树 时,即 LR 插入,采用 LR 旋转调整RR 单旋 转化为 LL 插入,再将 A 作为根结点进行 LL 单旋 (先 RR 再 LL)
示意图:
1 2 3 4 5 6 7 AVLTree LRRotation (AVLTree A) { A->left = RRRotation(A->left); return LLRotation(A); } 123456
总结:叫 LR 双旋是从上到下看,而实际先 RR 单旋再 LL 单旋是从下往上的过程
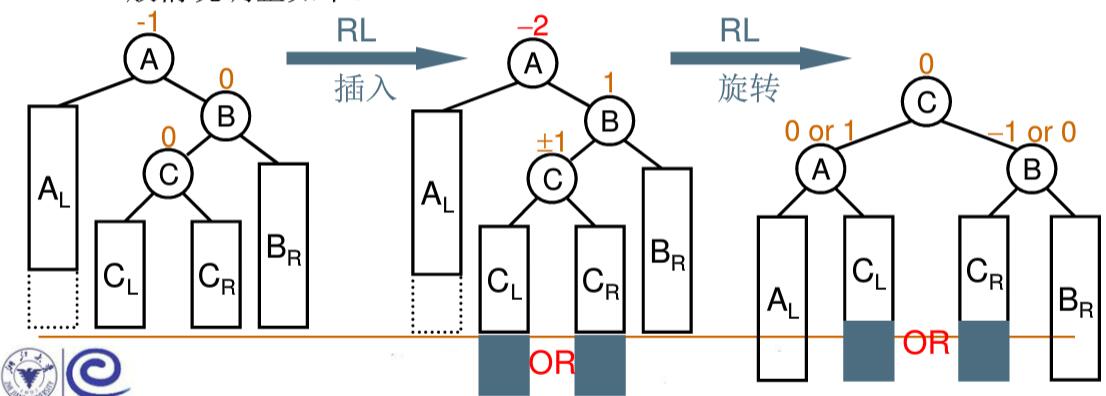
4. RL 双旋 当”插入结点”(CL 或者 CR)是”被破坏平衡结点”(A)右子树 的左子树 时,即 RL 插入,采用 RL 旋转调整LL 单旋 转化为 RR 插入,再将 A 作为根结点进行 RR单旋 (先 LL 再 RR)
示意图:
1 2 3 4 5 6 7 AVLTree RLRotation (AVLTree A) { A->right = LLRotation(A->right); return RRRotation(A); } 123456
总结:叫 RL 双旋是从上到下看,而实际先 LL 单旋再 RR 单旋是从下往上的过程
堆 1. 什么是堆 优先队列(priority Queue):特殊的”队列”,取出元素的顺序是依照元素的优先级(关键字)大小,而不是元素进入队列的先后顺序,以完全二叉树 存储
两个特性
2. 堆的抽象数据类型描述
1. 插入 插入数组最后一个位置,再从下往上找合适地方
2. 删除 删除根结点,将数组最后一个位置的数取到根结点,从上往下找合适地方
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 #include <stdio.h> #include <malloc.h> #define MaxData 100000 #define ERROR -1 typedef int ElementType;typedef struct HeapStruct *MaxHeap ;struct HeapStruct { ElementType *Elements; int Size; int Capacity; }; MaxHeap Create (int MaxSize) ; bool IsFull (MaxHeap H) bool Insert (MaxHeap H,ElementType item) bool IsEmpty (MaxHeap H) ElementType DeleteMax (MaxHeap H) ; void LevelOrderTraversal (MaxHeap H) MaxHeap Create (int MaxSize) { MaxHeap H = (MaxHeap)malloc (sizeof (struct HeapStruct)); H->Elements = (ElementType *)malloc ((MaxSize+1 ) * sizeof (ElementType)); H->Size = 0 ; H->Capacity = MaxSize; H->Elements[0 ] = MaxData; return H; } bool Insert (MaxHeap H,ElementType item) if (IsFull(H)){ printf ("堆已满,无法插入!\n" ); return false ; } int i = ++H->Size; for (;H->Elements[i/2 ] < item;i/=2 ) H->Elements[i] = H->Elements[i/2 ]; H->Elements[i] = item; return true ; } ElementType DeleteMax (MaxHeap H) { int parent,child; ElementType Max,tmp; if (IsEmpty(H)){ printf ("堆为空,无法删除!\n" ); return ERROR; } Max = H->Elements[1 ]; tmp = H->Elements[H->Size--]; for (parent=1 ;parent*2 <=H->Size;parent=child){ child = 2 * parent; if ((child!=H->Size) &&(H->Elements[child] < H->Elements[child+1 ])) child++; if (H->Elements[child] <= tmp) break ; else H->Elements[parent] = H->Elements[child]; } H->Elements[parent] = tmp; return Max; } bool IsFull (MaxHeap H) return (H->Size == H->Capacity); } bool IsEmpty (MaxHeap H) return !H->Size; } void LevelOrderTraversal (MaxHeap H) int i; printf ("层序遍历的结果是:" ); for (i = 1 ;i<=H->Size;i++){ printf ("%d " ,H->Elements[i]); } printf ("\n" ); } int main () MaxHeap H; int MaxSize = 100 ; H = Create(MaxSize); Insert(H,55 ); Insert(H,66 ); Insert(H,44 ); Insert(H,33 ); Insert(H,11 ); Insert(H,22 ); Insert(H,88 ); Insert(H,99 ); LevelOrderTraversal(H); DeleteMax(H); LevelOrderTraversal(H); DeleteMax(H); LevelOrderTraversal(H); DeleteMax(H); LevelOrderTraversal(H); DeleteMax(H); LevelOrderTraversal(H); return 0 ; } 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124
3. 最小堆的建立 不是初始化堆啦!已经存在的 N 个元素 按最小堆的要求存放在一个一维数组中
0. 注意 对于一组相同数据,插入建堆和调整建堆建出来的堆也许不一样
1. 插入建堆 通过插入,将 N 个元素一个一个相继插入到一个初始为空 的堆中去,其时间代价最大是 O(NlogN)O(N logN)O (Nl og N )(每次插入是 logN,总共 N 次)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <iostream> #include <malloc.h> const int MinData = -100000 ; const int MaxSize = 1005 ; using namespace std ;typedef struct HeapStruct *Heap ;struct HeapStruct { int *data; int size; int capacity; }; #include <iostream> #include <malloc.h> const int MinData = -100000 ; const int MaxSize = 1005 ; using namespace std ;typedef struct HeapStruct *Heap ;struct HeapStruct { int *data; int size; int capacity; }; Heap Create () { Heap H; H = (Heap)malloc (sizeof (struct HeapStruct)); H->data = (int *)malloc (sizeof (int ) * (MaxSize+1 )); H->size = 0 ; H->capacity = MaxSize; H->data[0 ] = MinData; return H; } void Insert (Heap H,int x) int i = ++H->size; for (;H->data[i/2 ]>x;i/=2 ) H->data[i] = H->data[i/2 ]; H->data[i] = x; } void bl (Heap H) for (int i=1 ;i<=H->size;i++) cout <<H->data[i]<<" " ; } int main () Heap H; H = Create(); int n; cin >>n; for (int i=0 ;i<n;i++){ int t; cin >>t; Insert(H,t); } bl(H); return 0 ; } 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
2. 调整建堆 将 N 个元素直接按顺序存入,再调整各结点的位置(简单说来,对于从最后一个有孩子结点的结点来说,其本身结点和孩子结点共同构成”子最小堆”,借助前面删除的想法,对每个”子最小堆”排序,当排序完成,整个最小堆也建立成功),时间代价是 O(n)O(n)O (n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> #include <malloc.h> const int MinData = -100000 ; const int MaxSize = 1005 ; using namespace std ;typedef struct HeapStruct *Heap ;struct HeapStruct { int *data; int size; int capacity; }; Heap Create () { Heap H; H = (Heap)malloc (sizeof (struct HeapStruct)); H->data = (int *)malloc (sizeof (int ) * (MaxSize+1 )); H->size = 0 ; H->capacity = MaxSize; H->data[0 ] = MinData; return H; } void sort (Heap H,int i) int child,parent; int tmp = H->data[i]; for (parent = i;parent*2 <=H->size;parent = child){ child = 2 * parent; if ((child!=H->size) && (H->data[child+1 ] < H->data[child])) child++; if (H->data[child] >= tmp) break ; else H->data[parent] = H->data[child]; } H->data[parent] = tmp; } void adjust (Heap H) int i= H->size/2 ; for (;i>0 ;i--){ sort(H,i); } } void bl (Heap H) for (int i=1 ;i<=H->size;i++){ cout <<H->data[i]<<" " ; } cout <<endl ; } int main () Heap H; H = Create(); int n; cin >>n; for (int i=0 ;i<n;i++) cin >>H->data[++H->size]; adjust(H); bl(H); return 0 ; }
哈夫曼树 1. 定义 带权路径长度(WPL) :设二叉树有 nnn 个叶子结点,每个叶子结点带有权值 wkw_kw**k ,从根结点到每个叶子结点的长度为 lkl_kl**k ,则每个叶子结点的带权路径长度之和就是:WPL = ∑nk=1wklk\sum_{k=1}^{n}w_kl_k∑k =1nw kl k
最优二叉树或哈夫曼树:WPL 最小的二叉树
2. 哈夫曼树的构造
3. 哈夫曼树的特点
没有度为 1 的结点
n 个叶结点的哈夫曼树共有 2n-1 个结点
哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树
对同一组权值,可能存在不同构的多棵哈夫曼树
4. 最小堆实现哈夫曼树 刚开始挺懵逼,堆里面怎么还出哈夫曼树了呢…看姥姥留言堆里本来就是放东西的,既然可以放数…那为什么不能放树,醍醐灌顶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 #include <iostream> #include <malloc.h> #define MaxSize 1000 #define MinData -1000 int A[] = {1 ,3 ,5 ,8 }; int A_length = 4 ; typedef struct HeapStruct *MinHeap ;typedef struct TreeNode *HuffmanTree ;struct HeapStruct { HuffmanTree *data; int size; int capacity; }; struct TreeNode { int weight; HuffmanTree Left; HuffmanTree right; }; using namespace std ;MinHeap create () ; HuffmanTree Create () ; void sort (MinHeap H,int i) void adjust (MinHeap H) void BuildMinHeap (MinHeap H) HuffmanTree Delete (MinHeap H) ; void Insert (MinHeap H,HuffmanTree Huff) void PreOrderTraversal (HuffmanTree Huff) HuffmanTree Huffman (MinHeap H) ; MinHeap create () { MinHeap H; HuffmanTree Huff; H = (MinHeap)malloc (sizeof (struct HeapStruct)); H->data = (HuffmanTree *)malloc (sizeof (struct TreeNode) * (MaxSize+1 )); H->capacity = MaxSize; H->size = 0 ; Huff = Create(); Huff->weight = MinData; H->data[0 ] = Huff; return H; } HuffmanTree Create () { HuffmanTree Huff; Huff = (HuffmanTree)malloc (sizeof (struct TreeNode)); Huff->weight = 0 ; Huff->Left = NULL ; Huff->right = NULL ; return Huff; } void sort (MinHeap H,int i) int parent,child; int tmp = H->data[i]->weight; for (parent=i;parent*2 <=H->size;parent = child){ child = 2 * parent; if ((child!=H->size) && (H->data[child+1 ]->weight < H->data[child]->weight)) child++; if (H->data[child]->weight >= tmp) break ; else H->data[parent] = H->data[child]; } H->data[parent]->weight = tmp; } void adjust (MinHeap H) for (int i =H->size/2 ;i>0 ;i--) sort(H,i); } void BuildMinHeap (MinHeap H) HuffmanTree Huff; for (int i=0 ;i<A_length;i++){ Huff = Create(); Huff->weight = A[i]; H->data[++H->size] = Huff; } adjust(H); } HuffmanTree Delete (MinHeap H) { int parent,child; HuffmanTree T = H->data[1 ]; HuffmanTree tmp = H->data[H->size--]; for (parent=1 ;parent*2 <=H->size;parent = child){ child = 2 * parent; if ((child!=H->size) && (H->data[child+1 ]->weight < H->data[child]->weight)) child++; if (H->data[child]->weight >= tmp->weight) break ; else H->data[parent] = H->data[child]; } H->data[parent] = tmp; return T; } void Insert (MinHeap H,HuffmanTree Huff) int weight = Huff->weight; int i = ++H->size; for (;H->data[i/2 ]->weight > weight;i/=2 ) H->data[i] = H->data[i/2 ]; H->data[i] = Huff; } void PreOrderTraversal (HuffmanTree Huff) if (Huff){ cout <<Huff->weight<<" " ; PreOrderTraversal(Huff->Left); PreOrderTraversal(Huff->right); } } HuffmanTree Huffman (MinHeap H) { HuffmanTree T; BuildMinHeap(H); int times = H->size; for (int i=1 ;i<times;i++){ T = (HuffmanTree)malloc (sizeof (struct TreeNode)); T->Left = Delete(H); T->right = Delete(H); T->weight = T->Left->weight + T->right->weight; Insert(H,T); } T = Delete(H); return T; } int main () MinHeap H; HuffmanTree Huff; H = create(); Huff = Huffman(H); PreOrderTraversal(Huff); return 0 ; }
并查集 1. 数组存储的基础实现 此时并查集用一个结构体存储,data 存值(下标+1),parent 存父结点下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> #include <cstring> #define MaxSize 1000 typedef int ElementType;typedef struct { ElementType Data; int parent; }SetType; using namespace std ;int Find (SetType s[],ElementType x) int i; for (i=0 ;i<MaxSize && s[i].Data!=x;i++); if (MaxSize <= i) return -1 ; for (;s[i].parent >= 0 ;i = s[i].parent); return i; } void Union (SetType s[],ElementType x1,ElementType x2) int root1 = Find(s,x1); int root2 = Find(s,x2); if (root1 != root2){ s[root1].parent = root2; } } int main () SetType s[MaxSize]; for (int i=0 ;i<MaxSize;i++){ s[i].Data = i+1 ; s[i].parent = -1 ; } cout <<Find(s,5 )<<endl ; Union(s,3 ,5 ); cout <<Find(s,4 )<<endl ; cout <<Find(s,3 )<<endl ; Union(s,1 ,3 ); Union(s,2 ,4 ); Union(s,8 ,6 ); cout <<Find(s,6 )<<endl ; cout <<Find(s,8 )<<endl ; return 0 ; } 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
2. 优化存储结构 观察上面的结构体,其实值和数组下标差一,那可以直接把值 1 ~ n 映射为下标的 0 ~ n-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <cstdio> #include <iostream> #define MaxSize 10005 typedef int SetType; using namespace std ;void Init (SetType s[]) for (int i=0 ;i<MaxSize;i++) s[i] = -1 ; } int Find (SetType s[],int x) for (;s[x]>=0 ;x = s[x]); return x; } void Union (SetType s[],int x1,int x2) s[x1] = x2; } int main () SetType s[MaxSize]; Init(s); cout <<Find(s,5 )<<endl ; Union(s,3 ,5 ); cout <<Find(s,4 )<<endl ; cout <<Find(s,3 )<<endl ; Union(s,1 ,3 ); Union(s,2 ,4 ); Union(s,8 ,6 ); cout <<Find(s,6 )<<endl ; cout <<Find(s,8 )<<endl ; return 0 ; }
3. 按秩归并优化 Union 当多次并操作时,其中一个操作数固定,另一个操作数一直递增或一直递减时,树会退化成单链表
1. 根据树高归并 一种解决办法是每次将 “矮” 的树挂到 “高”树上去树高 信息存储在根结点的数组值中(之前根结点的数组值都存的 -1,现在存 -树高)
1 2 3 4 5 6 7 8 9 10 11 12 13 void Union (SetType s[],int x1,int x2) if (s[x1] < s[x2]){ s[x2] = x1; }else { if (s[x1] == s[x2]) s[x2]--; s[x1] = x2; } } 123456789101112
2. 根据规模归并 另一种解决办法是规模小的树挂到规模更高的树上去规模 信息存储在根结点的数组值中(之前根结点的数组值都存的 -1,现在存 -元素个数)
1 2 3 4 5 6 7 8 9 10 11 12 13 void Union (SetType s[],int x1,int x2) if (s[x1] < s[x2]){ s[x1] += s[x2]; s[x2] = x1; }else { s[x2] += s[x1]; s[x1] = x2; } } 123456789101112
4. 路径压缩优化 Find 查找不可避免的越查越深,路径压缩可以把待查找结点与根结点之间的一系列结点的上一结点都变为根结点,即当查找 D 后:
1 2 3 4 5 6 7 int Find (SetType s[],int x) if (s[x] < 0 ) return x; else return s[x] = Find(s,s[x]); }
图 图的定义 1. 什么是图
表示”多对多”的关系
包含
一组顶点:通常用 V(Vertex)表示顶点集合
一组边:通常用 E(Edge)表示边的集合
边是顶点对:(v,w)∈ E,其中 v,w ∈ V v—w
有向边 表示从 v 指向 w 的边(单行线) v→w
不考虑重边和自回路
2. 常见术语
无向图:图中所有的边无所谓方向
有向图:图中的边可能是双向,也可能是单向的,方向是很重要的
权值:给图中每条边赋予的值,可能有各种各样的现实意义
网络:带权值的图
邻接点:有边直接相连的顶点
出度:从某顶点发出的边数
入度:指向某顶点的边数
稀疏图:顶点很多而边很少的图
稠密图:顶点多边也多的图
完全图:对于给定的一组顶点,顶点间都存在边
3. 抽象数据类型定义
1. 邻接矩阵表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 #include <stdio.h> #include <stdlib.h> #define MaxVertexNum 100 typedef int weightType;typedef int Vertex;typedef int DataType;typedef struct GNode *ptrToGNode ;struct GNode { int Nv; int Ne; weightType G[MaxVertexNum][MaxVertexNum]; DataType Data[MaxVertexNum]; }; typedef ptrToGNode MGraph;typedef struct ENode *ptrToENode ;struct ENode { Vertex V1,V2; weightType Weight; }; typedef ptrToENode Edge;MGraph Create (int VertexNum) { Vertex v,w; MGraph Graph; Graph = (MGraph)malloc (sizeof (struct GNode)); Graph->Nv = VertexNum; Graph->Ne = 0 ; for (v=0 ;v<VertexNum;v++) for (w=0 ;w<VertexNum;w++) Graph->G[v][w] = 0 ; return Graph; } MGraph Insert (MGraph Graph,Edge E) { Graph->G[E->V1][E->V2] = E->Weight; Graph->G[E->V2][E->V1] = E->Weight; } MGraph BuildGraph () { MGraph Graph; Edge E; Vertex V; int Nv,i; scanf ("%d" ,&Nv); Graph = Create(Nv); scanf ("%d" ,&(Graph->Ne)); if (Graph->Ne != 0 ){ E = (Edge)malloc (sizeof (struct ENode)); for (i=0 ;i<Graph->Ne;i++){ scanf ("%d %d %d" ,&E->V1,&E->V2,&E->Weight); Insert(Graph,E); } } return Graph; } void print (MGraph Graph) Vertex v,w; for (v=0 ;v<Graph->Nv;v++){ for (w=0 ;w<Graph->Nv;w++) printf ("%d " ,Graph->G[v][w]); printf ("\n" ); } } int main () MGraph Graph; Graph = BuildGraph(); print (Graph); return 0 ; }
简洁版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <stdio.h> #include <stdlib.h> #define MAXN 100 int G[MAXN][MAXN],Nv,Ne;void BuildGraph () int i,j,v1,v2,w; scanf ("%d" ,&Nv); for (i=0 ;i<Nv;i++) for (j=0 ;j<Nv;j++) G[i][j] = 0 ; scanf ("%d" ,&Ne); for (i=0 ;i<Ne;i++){ scanf ("%d %d %d" ,&v1,&v2,&w); G[v1][v2] = w; G[v2][v1] = w; } } void print () int i,j; for (i=0 ;i<Nv;i++){ for (j=0 ;j<Nv;j++) printf ("%d " ,G[i][j]); printf ("\n" ); } } int main () BuildGraph(); print (); return 0 ; }
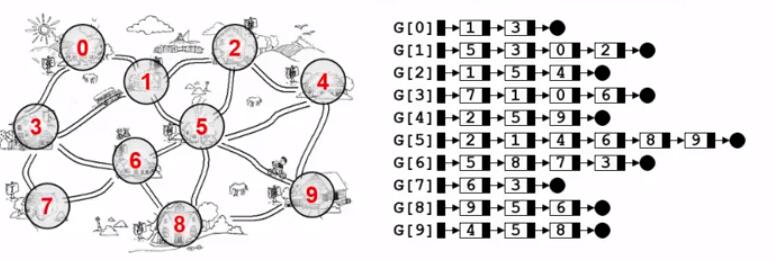
2. 邻接表表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 #include <stdio.h> #include <stdlib.h> #define MaxVertexNum 100 typedef int Vertex; typedef int DataType; typedef int weightType; typedef struct ENode *ptrToENode ;struct ENode { Vertex V1,V2; weightType Weight; }; typedef ptrToENode Edge;typedef struct AdjVNode *ptrToAdjVNode ;struct AdjVNode { Vertex AdjV; weightType Weight; ptrToAdjVNode Next; }; typedef struct VNode { ptrToAdjVNode FirstEdge; DataType Data; }AdjList[MaxVertexNum]; typedef struct GNode *ptrToGNode ;struct GNode { int Nv; int Ne; AdjList G; }; typedef ptrToGNode LGraph;LGraph create (int VertexNum) { Vertex v,w; LGraph Graph; Graph = (LGraph)malloc (sizeof (struct GNode)); Graph->Nv = VertexNum; Graph->Ne = 0 ; for (v=0 ;v<Graph->Nv;v++) Graph->G[v].FirstEdge = NULL ; return Graph; } void InsertEdge (LGraph Graph,Edge E) ptrToAdjVNode newNode; newNode = (ptrToAdjVNode)malloc (sizeof (struct AdjVNode)); newNode->AdjV = E->V2; newNode->Weight = E->Weight; newNode->Next = Graph->G[E->V1].FirstEdge; Graph->G[E->V1].FirstEdge = newNode; newNode = (ptrToAdjVNode)malloc (sizeof (struct AdjVNode)); newNode->AdjV = E->V1; newNode->Weight = E->Weight; newNode->Next = Graph->G[E->V2].FirstEdge; Graph->G[E->V2].FirstEdge = newNode; } LGraph BuildGraph () { LGraph Graph; Edge E; Vertex V; int Nv,i; scanf ("%d" ,&Nv); Graph = create(Nv); scanf ("%d" ,&(Graph->Ne)); if (Graph->Ne != 0 ){ for (i=0 ;i<Graph->Ne;i++){ E = (Edge)malloc (sizeof (struct ENode)); scanf ("%d %d %d" ,&E->V1,&E->V2,&E->Weight); InsertEdge(Graph,E); } } return Graph; } void print (LGraph Graph) Vertex v; ptrToAdjVNode tmp; for (v=0 ;v<Graph->Nv;v++){ tmp = Graph->G[v].FirstEdge; printf ("%d " ,v); while (tmp){ printf ("%d " ,tmp->AdjV); tmp = tmp->Next; } printf ("\n" ); } } int main () LGraph Graph; Graph = BuildGraph(); print (Graph); return 0 ; }
简化版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <stdio.h> #include <stdlib.h> #define MaxVertexNum 100 typedef struct AdjVNode *AdjList ;struct AdjVNode { int weight; int adjv; AdjList next; }; AdjList Graph[MaxVertexNum]; int Ne,Nv;void BuildGraph () int i; int v1,v2,w; AdjList NewNode; scanf ("%d" ,&Nv); for (i=0 ;i<Nv;i++){ Graph[i] = (AdjList)malloc (sizeof (struct AdjVNode)); Graph[i]->adjv = i; Graph[i]->next = NULL ; } scanf ("%d" ,&Ne); for (i=0 ;i<Ne;i++){ scanf ("%d %d %d" ,&v1,&v2,&w); NewNode = (AdjList)malloc (sizeof (struct AdjVNode)); NewNode->adjv = v1; NewNode->weight = w; NewNode->next = Graph[v2]->next; Graph[v2]->next = NewNode; NewNode = (AdjList)malloc (sizeof (struct AdjVNode)); NewNode->adjv = v2; NewNode->weight = w; NewNode->next = Graph[v1]->next; Graph[v1]->next = NewNode; } } void print () AdjList tmp; int i; for (i=0 ;i<Nv;i++){ tmp = Graph[i]; while (tmp){ printf ("%d " ,tmp->adjv); tmp = tmp->next; } printf ("\n" ); } } int main () BuildGraph(); print (); return 0 ; }
图的遍历 1. DFS 深度优先搜索(Depth First Search),类似于树的先序遍历
1 2 3 4 5 6 7 void DFS ( Vertex V ) visited[ V ] = true ; for ( V 的每个邻接点 W ) if ( !visited[ W ]) DFS( W ); } 123456
若有 N 个顶点、E 条边,时间复杂度是
用邻接表存储,O(N + E)
用邻接矩阵存储,O(N2^22)
2. BFS 广度优先搜索(Breadth First Search),相当于树的层序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void BFS ( Vertex V ) queue <Vertex> q; visited[V] = true ; q.push(V); while (!q.empty()){ V = q.front(); q.pop(); for ( V 的每个邻接点 W ){ if ( !visited[ W ]){ visited[W] = true ;s q.push(W); } } } }
若有 N 个顶点、E 条边,时间复杂度是
用邻接表存储,O(N + E)
用邻接矩阵存储,$O(n^{2})$
最短路径问题 1. 概述 1. 抽象 在网络(带权图)中,求两个不同顶点之间的所有路径中,边的权值之和最小的那一条路径
这条路径就是两点之间的最短路径 (ShorttestPath)
第一个顶点为源点 (Source)
最后一个顶点为终点 (Destination)
2. 分类
2. 无权图的单源最短路算法 按照递增(非递减)的顺序找出到各个顶点的最短路
1 2 3 4 5 6 7 8 9 10 11 12 void Unweighted ( Vertex s) queue <Vertex> q; q.push(s); wile(!q.empty()){ v = q.front(); q.pop(); for ( V 的每个临界点 W){ dist[W] = dist[v] + 1 ; path[W] = v; q.push(W); } } }
3. 有权图的单源最短路算法 Dijkstra 算法
令 S = {源点s + 已经确定了最短路径的顶点 $v_i$}
对任一未收录的顶点 v,定义 dist[v] 为 s 到 v 的最短路径长度,但该路径仅经过 S 中的顶点。即路径 {s→($v_i$∈S)→v} 的最小长度
若路径是按照递增(非递减)的顺序生成的,则
真正的最短路必须只经过 S 中的顶点
每次从未收录的顶点中选一个 dist 最小的收录
增加一个 v 进入 S,可能影响另外一个 w 的 dist 值
dist[w] = min{dist[w],dist[v] + 的权重}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void Dijkstra ( Vertex s ) while (1 ){ V = 未收录顶点中dist最小值; if ( 这样的V不存在 ) break ; collected[V] = true ; for ( V 的每个邻接点 W ) if ( collected[W] == false ) if (dist[V] + E<V,W> < dist[W]){ dist[W] = dist[V] + E<V,W>; path[W] = V; } } }
取出未收录顶点中dist最小值 和 更新dist[W]的操作可以考虑两种方法:
直接扫描所有未收录顶点 ——O(|V|)
T = O($|V|^2$ + |E|) ——稠密图效果更好
将dist存在最小堆中 ——O(log|V|)
更新dist[w]的值 —O(log|V|)
T = O(|E|log|V|) —— 稀疏图效果更好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include <iostream> #include <stdlib.h> #define Inf 1000000 #define Init -1 #define MaxVertex 100 typedef int Vertex;int G[MaxVertex][MaxVertex];int dist[MaxVertex]; int path[MaxVertex]; int collected[MaxVertex]; int Nv; int Ne; using namespace std ;void build () Vertex v1,v2; int w; cin >>Nv; for (int i=1 ;i<=Nv;i++) for (int j=1 ;j<=Nv;j++) G[i][j] = 0 ; for (int i=1 ;i<=Nv;i++) path[i] = Init; for (int i=0 ;i<=Nv;i++) dist[i] = Inf; for (int i=1 ;i<=Nv;i++) collected[i] = false ; cin >>Ne; for (int i=0 ;i<Ne;i++){ cin >>v1>>v2>>w; G[v1][v2] = w; } } void crate (Vertex s) dist[s] = 0 ; collected[s] = true ; for (int i=1 ;i<=Nv;i++) if (G[s][i]){ dist[i] = G[s][i]; path[i] = s; } } Vertex FindMin (Vertex s) { int min = 0 ; for (Vertex i=1 ;i<=Nv;i++) if (i != s && dist[i] < dist[min] && !collected[i]) min = i; return min; } void Dijkstra (Vertex s) crate(s); while (true ){ Vertex V = FindMin(s); if (!V) break ; collected[V] = true ; for (Vertex W=1 ;W<=Nv;W++) if (!collected[W] && G[V][W]){ if (dist[V] + G[V][W] < dist[W]){ dist[W] = G[V][W] + dist[V]; path[W] = V; } } } } void output () for (int i=1 ;i<=Nv;i++) cout <<dist[i]<<" " ; cout <<endl ; for (int i=1 ;i<=Nv;i++) cout <<path[i]<<" " ; cout <<endl ; } int main () build(); Dijkstra(1 ); output(); return 0 ; }
4. 多源最短路算法
Floyd 算法
$D^k[i][j]$= 路径{ i →{$l$≤ $k$} → j } 的最小长度
$D^0,D^1,…,D^{|V|-1}[i][j]$即给出了 i 到 j 的真正最短距离
最初的 $D^{-1}$ 是全 0 的邻接矩阵
若 i 和 j 不直接相连,初始化为无穷大
当 $D^{k-1}$已经完成,递推到 $D^k$时:
或者 k 不属于 最短路径 { i →{$ l$ ≤ $k$ } → j },则
或者$ k $属于最短路径 { i →{ $l≤ $$k$} → j },则该路径必定由两段最短路径组成:$D^k[i][j]=D^{k-1}[i][k]+D^{k-1}[k][j]$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 void Floyd () for ( i = 0 ; i < N; i++ ) for ( j = 0 ; j < N; j++ ){ D[i][j] = G[i][j]; path[i][j] = -1 ; } for ( k = 0 ; k < N; k++ ) for ( i = 0 ; i< N; i++) for ( j = 0 ; j < N; j++ ) if ( D[i][k] + D[k][j] < D[i][j] ) { D[i][j] = D[i][k] + D[k][j]; path[i][j] = k; } } #include <iostream> #include <stdlib.h> #define INF 1000000 #define MaxVertex 100 typedef int Vertex;int G[MaxVertex][MaxVertex];int dist[MaxVertex][MaxVertex]; int path[MaxVertex][MaxVertex]; int Nv; int Ne; using namespace std ;void build () Vertex v1,v2; int w; cin >>Nv; for (int i=1 ;i<=Nv;i++) for (int j=1 ;j<=Nv;j++) G[i][j] = INF; cin >>Ne; for (int i=0 ;i<Ne;i++){ cin >>v1>>v2>>w; G[v1][v2] = w; G[v2][v1] = w; } } void Floyd () for (Vertex i=1 ;i<=Nv;i++) for (Vertex j=1 ;j<=Nv;j++){ dist[i][j] = G[i][j]; path[i][j] = -1 ; } for (Vertex k=1 ;k<=Nv;k++) for (Vertex i=1 ;i<=Nv;i++) for (Vertex j=1 ;j<=Nv;j++) if (dist[i][k] + dist[k][j] < dist[i][j]){ dist[i][j] = dist[i][k] + dist[k][j]; path[i][j] = k; } } void output () for (Vertex i=1 ;i<=Nv;i++){ for (Vertex j=1 ;j<=Nv;j++) cout <<dist[i][j]<<" " ; cout <<endl ; } cout <<endl ; for (Vertex i=1 ;i<=Nv;i++){ for (Vertex j=1 ;j<=Nv;j++) cout <<path[i][j]<<" " ; cout <<endl ; } } int main () build(); Floyd(); output(); return 0 ; }
最小生成树问题 1. 什么是最小生成树
2. 贪心算法
什么是 “贪”:每一步都是最好的
什么是 “好”:权重最小的边
需要约束:
只能用图里有的边
只能正好用掉 |V|-1 条边
不能有回路
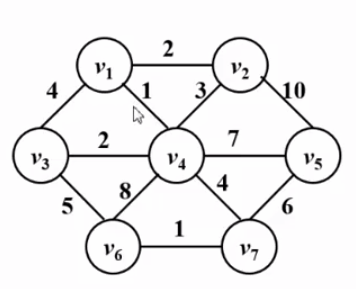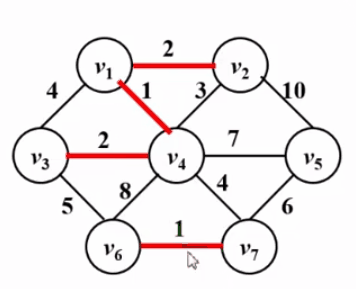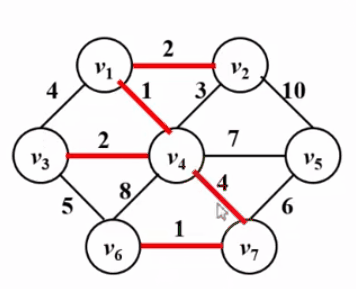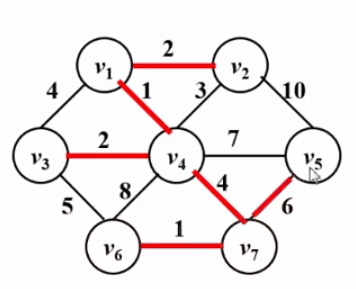
1. Prim 算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Prim () MST = {s}; while (1 ){ V = 未收录顶点中dist最小者; if ( 这样的V不存在 ) break ; dist[V] = 0 ; for ( V 的每个邻接点 W ) if ( dist[W]!= 0 ) if ( E<V,W> < dist[w] ){ dist[W] = E<V,W>; parent[W] = V; } } if ( MST 中收的顶点不到|V|个) Error ( "图不连通" ); }
时间复杂度:T = O($|V|^2$) —— 稠密图合算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 #include <iostream> #include <vector> #define INF 100000 #define MaxVertex 105 typedef int Vertex; int G[MaxVertex][MaxVertex];int parent[MaxVertex]; int dist[MaxVertex]; int Nv; int Ne; int sum; using namespace std ; vector <Vertex> MST; void build () Vertex v1,v2; int w; cin >>Nv>>Ne; for (int i=1 ;i<=Nv;i++){ for (int j=1 ;j<=Nv;j++) G[i][j] = 0 ; dist[i] = INF; parent[i] = -1 ; } for (int i=0 ;i<Ne;i++){ cin >>v1>>v2>>w; G[v1][v2] = w; G[v2][v1] = w; } } void IniPrim (Vertex s) dist[s] = 0 ; MST.push_back(s); for (Vertex i =1 ;i<=Nv;i++) if (G[s][i]){ dist[i] = G[s][i]; parent[i] = s; } } Vertex FindMin () { int min = INF; Vertex xb = -1 ; for (Vertex i=1 ;i<=Nv;i++) if (dist[i] && dist[i] < min){ min = dist[i]; xb = i; } return xb; } void output () cout <<"被收录顺序:" <<endl ; for (Vertex i=1 ;i<=Nv;i++) cout <<MST[i]<<" " ; cout <<"权重和为:" <<sum<<endl ; cout <<"该生成树为:" <<endl ; for (Vertex i=1 ;i<=Nv;i++) cout <<parent[i]<<" " ; } void Prim (Vertex s) IniPrim(s); while (1 ){ Vertex v = FindMin(); if (v == -1 ) break ; sum += dist[v]; dist[v] = 0 ; MST.push_back(v); for (Vertex w=1 ;w<=Nv;w++) if (G[v][w] && dist[w]) if (G[v][w] < dist[w]){ dist[w] = G[v][w]; parent[w] = v; } } } int main () build(); Prim(1 ); output(); return 0 ; }
2. Kruskal 算法
1 2 3 4 5 6 7 8 9 10 11 12 13 void Kruskal ( Graph G ) MST = { }; while ( MST 中不到|V|-1 条边 && E中还有边 ) { 从 E 中取一条权重最小的边 E<V,W>; 将 E<V,W> 从 E 中删除; if ( E<V,W> 不在 MST 中构成回路 ) 将 E<V,W> 加入MST; else 彻底无视 E<V,W>; } if ( MST 中不到|V|-1 条边 ) Error("图不连通" ); }
时间复杂度:T = O(|E|log|E|) —— 稀疏图合算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 #include <iostream> #include <string> #include <vector> #include <queue> #define INF 100000 #define MaxVertex 105 typedef int Vertex; int G[MaxVertex][MaxVertex];int parent[MaxVertex]; int Nv; int Ne; int sum; using namespace std ; struct Node { Vertex v1; Vertex v2; int weight; bool operator < (const Node &a) const { return weight>a.weight; } }; vector <Node> MST; priority_queue<Node> q; void build () Vertex v1,v2; int w; cin >>Nv>>Ne; for (int i=1 ;i<=Nv;i++){ for (int j=1 ;j<=Nv;j++) G[i][j] = 0 ; parent[i] = -1 ; } for (int i=0 ;i<Ne;i++){ cin >>v1>>v2>>w; struct Node tmpE ; tmpE.v1 = v1; tmpE.v2 = v2; tmpE.weight = w; q.push(tmpE); } } int Find (int x) if (parent[x] < 0 ) return x; else return parent[x] = Find(parent[x]); } void Union (int x1,int x2) x1 = Find(x1); x2 = Find(x2); if (parent[x1] < parent[x2]){ parent[x1] += parent[x2]; parent[x2] = x1; }else { parent[x2] += parent[x1]; parent[x1] = x2; } } void Kruskal () while (MST.size()!= Nv-1 && !q.empty()){ Node E = q.top(); q.pop(); if (Find(E.v1) != Find(E.v2)){ sum += E.weight; Union(E.v1,E.v2); MST.push_back(E); } } } void output () cout <<"被收录顺序:" <<endl ; for (Vertex i=0 ;i<Nv;i++) cout <<MST[i].weight<<" " ; cout <<"权重和为:" <<sum<<endl ; for (Vertex i=1 ;i<=Nv;i++) cout <<parent[i]<<" " ; cout <<endl ; } int main () build(); Kruskal(); output(); return 0 ; }
排序 散列查找 1. 基本思想
以关键字 key 为自变量,通过一个确定的函数 h(散列函数 ),计算出对应的函数值 h(key),作为数据对象的存储地址
可能不同的关键字会映射到同一个散列地址上,即 $h(key_i)=h(key_j)$(当 $key_i$≠ $key_j$),称为“冲突 ”——需要某种冲突解决策略
2. 基本工作
计算位置 :构造散列函数确定关键词存储位置解决冲突 :应用某种策略解决多个关键词位置相同的问题
时间复杂度几乎为是常数:O(1)
3. 散列函数的构造 1. 考虑因素
计算简单 ,以便提高转换速度关键词对应的地址空间分布均匀 ,以尽量减少冲突
2. 数字关键词 1. 直接定址法 取关键词的某个线性函数值为散列地址,即:h(key) = a x key + b (a、b为常数)
2. 除留余数法 散列函数为:h(key) = key mod p (p 一般取素数)
3. 数字分析法 分析数字关键字在各位上的变化情况,取比较随机的位作为散列地址
4. 折叠法 把关键词分割成位数相同的几个部分,然后叠加
5. 平方取中法 将关键词平方,取中间几位
3. 字符串关键字 1. ASCII码加和法 h(key) = (Σkey[i]) mod TableSize
2. 前3个字符移位法 h(key) = (key[0]×$27^2$ + key[1]×27 + key[2])mod TableSize
3. 移位法 h(key) = $\begin{equation}\left(\sum_{i=0}^{n-1} \mathrm{key}[\mathrm{n}-\mathrm{i}-1] \times 32^{i}\right)\end{equation}$ mod TableSize
例子(移位法)
h(“abcde”) = ‘a’x$32^4$ + ‘b’x$32^3$ +’c’x$32^2$+ ‘d’x32 + ‘e’= (((‘a’x32+‘b’)x32+‘c’)x32+‘d’)x32+‘e’
1 2 3 4 5 6 Index Hash ( const char *Key,int TableSize) { unsigned int h = 0 ; while ( *Key != '\0' ) h = ( h << 5 ) + *Key++; return h % TableSize; }
4. 冲突处理方法 1. 常用策略
换个位置:开放地址法
同一位置的冲突对象组织在一起:链地址法
2. 开放定址法
一旦产生了冲突(该地址已有其它元素),就按某种规则去寻找另一空地址
若发生了第 i 次冲突,试探的下一个地址将增加 di_ii ,基本公式是: $h_i(key)=(h(key)+d_i)$mod TableSize (1 ≤ i ≤ TableSize)
di_ii 决定了不同的解决冲突方案
1. 线性探测 以增量序列 1,2,…, (TableSize - 1) 循环试探下一个存储地址
2. 平方探测法 以增量序列$1^2,-1^2,2^2,-2^2,…,q^2,-q^2$且 q ≤ ⌊ TableSize/2 ⌋ 循环试探下一个存储地址
如果散列表长度是某个 4k+3(k是正整数)形式的素数 时,平方探测法就可以探查到整个散列表空间
3. 双散列 $d_i$为$i*h_2(key)$,$h_2(key)$ 是另一个散列函数,探测序列成:$h_2(key),2h_2(key),3h_2(key)$
对任意 key,$h_2(key)\neq 0$
$h_2(key)$ = p - (key mod p) (p < TableSize,p、TableSize 都是素数)
4. 再散列 当散列表元素太多(即装填因子 α 太大)时,查找效率会下降
解决的方法是加倍扩大散列表,这个过程就叫”再散列”,扩大时,原有元素需要重新计算放置到新表中
3. 分离链接法 将相应位置上冲突的所有关键词存储在同一个单链表中
5. 抽象数据类型定义
1. 平方探测法实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <iostream> #include <stdlib.h> #include <cmath> #define MAXTABLESIZE 100000 typedef int Index;typedef int ElementType; typedef Index Position;typedef enum { Legitimate,Empty,Deleted } EntryType; typedef struct HashEntry Cell ;struct HashEntry { ElementType Data; EntryType Info; }; typedef struct HashTbl *HashTable ;struct HashTbl { int TableSize; Cell *Cells; }; using namespace std ;int NextPrime (int N) HashTable CreateTable ( int TableSize) ; Index Hash (int Key,int TableSize) ; int NextPrime (int N) int p = (N%2 )?N+2 :N+1 ; int i; while (p <= MAXTABLESIZE){ for (i = (int )sqrt (p);i>2 ;i--) if (!(p%i)) break ; if (i==2 ) break ; p += 2 ; } return p; } HashTable CreateTable ( int TableSize) { HashTable H; int i; H = (HashTable)malloc (sizeof (struct HashTbl)); H->TableSize = NextPrime(TableSize); H->Cells = (Cell *)malloc (sizeof (Cell)*H->TableSize); for (int i=0 ;i<H->TableSize;i++) H->Cells[i].Info = Empty; return H; } Position Find (HashTable H,ElementType Key) { Position CurrentPos,NewPos; int CNum = 0 ; CurrentPos = NewPos = Hash(Key,H->TableSize); while (H->Cells[NewPos].Info != Empty && H->Cells[NewPos].Data != Key){ if (++CNum % 2 ){ NewPos = CurrentPos + (CNum+1 )/2 *(CNum+1 )/2 ; while (H->TableSize <= NewPos){ NewPos -= H->TableSize; } }else { NewPos = CurrentPos - CNum/2 *CNum/2 ; while (NewPos < 0 ){ NewPos += H->TableSize; } } } return NewPos; } bool Insert ( HashTable H,ElementType Key,int i) Position Pos = i; Pos = Find(H,Key); if ( H->Cells[Pos].Info != Legitimate){ H->Cells[Pos].Info = Legitimate; H->Cells[Pos].Data = Key; } return true ; } Index Hash (int Key,int TableSize) { return Key % TableSize; } void output (HashTable H) for (int i=0 ;i<H->TableSize;i++) cout <<i<<" " <<H->Cells[i].Data<<endl ; } int main () HashTable H = CreateTable(9 ); int N; cin >>N; for (int i=0 ;i<N;i++){ int tmp; cin >>tmp; Insert(H,tmp,i); } output(H); return 0 ; }
2. 分离链接法实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 #include <iostream> #include <cstdlib> #include <cmath> #define MAXTABLESIZE 100000 typedef int Index;typedef int ElementType;typedef struct LNode *PtrToLNode ;struct LNode { ElementType Data; PtrToLNode Next; }; typedef PtrToLNode Position;typedef PtrToLNode List;typedef struct TblNode *HashTable ;struct TblNode { int TableSize; List Heads; }; using namespace std ;int NextPrime (int N) int p = (N%2 )?(N+2 ):(N+1 ); int i; while (p <= MAXTABLESIZE){ for (i = (int )sqrt (p);i>2 ;i--) if (!(p%i)) break ; if (i==2 ) break ; p += 2 ; } return p; } HashTable CreateTable ( int TableSize) { HashTable H; H = (HashTable)malloc (sizeof (struct TblNode)); H->TableSize = NextPrime(TableSize); H->Heads = (List)malloc (sizeof (struct TblNode) * H->TableSize); for (int i=0 ;i<H->TableSize;i++) H->Heads[i].Next = NULL ; return H; } Index Hash ( int TableSize,ElementType Key) { return Key%TableSize; } Position Find (HashTable H,ElementType Key) { Position p; Index pos; pos = Hash(H->TableSize,Key); p = H->Heads[pos].Next; while (p && p->Data != Key) p = p->Next; return p; } bool Insert (HashTable H,ElementType Key) Position p,NewCell; Index pos; p = Find(H,Key); if (!p){ NewCell = (Position)malloc (sizeof (struct LNode)); NewCell->Data = Key; pos = Hash(H->TableSize,Key); NewCell->Next = H->Heads[pos].Next; H->Heads[pos].Next = NewCell; return true ; }else { return false ; } } void output (HashTable H) for (int i=0 ;i<H->TableSize;i++){ cout <<i; List p = H->Heads[i].Next; while (p){ cout <<" " <<p->Data; p = p->Next; } cout <<endl ; } } void DestroyTable (HashTable H) Position P,tmp; for (int i=0 ;i<H->TableSize;i++){ P = H->Heads[i].Next; while ( P ){ tmp = P->Next; free (P); P = tmp; } } free (H->Heads); free (H); } int main () HashTable H = CreateTable(9 ); int N; cin >>N; for (int i=0 ;i<N;i++){ int tmp; cin >>tmp; Insert(H,tmp); } output(H); DestroyTable(H); return 0 ; }